Redis分布式锁
使用场景:
在课程下单以及领优惠卷中进行锁的实现,防止高并发下超卖现象的出现
例如: 两个线程都在请求下单或者领劵的业务,线程一查询库存,发现为一,同时线程二也查到库存为一,此时线程一和二都不会报错,都会进行扣减库存的操作,这样库存数量就变为了负一,出现了超卖!
尝试使用多线程中的synchronized加锁
在单体项目中,使用 synchronized 没有问题:
线程1先获取锁,其他线程尝试获取锁失败后会被阻塞等待;等线程1完成查库存、扣减库存等业务逻辑并释放锁后,其他线程才能获取锁继续执行。
在微服务架构下
同一个服务通常有多个实例,而 synchronized 是 JVM 级别的锁,只能保证单个实例内的线程互斥,无法约束其他实例。因此需要引入外部锁(例如分布式锁)来解决跨实例的并发问题。
采用Redis实现分布式锁
Redis实现分布式锁主要利用Redis的setnx命令。setnx是SET if not exists(如果不存在,则 SET)的简写。
- 获取锁:
#添加锁,NX是互斥、EX是设置超时时间
SET lock value NX EX 10
# 例如
SET lock:order:123 unique_id NX EX 10 里:
键:lock:order:123
值:unique_id
参数:NX(互斥)、EX 10(10秒过期)- 释放锁:
#安全释放锁,先判断是不是自己的锁再进行删除
#删除命令是:DEL key
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end命令分析
1. lock 和 value 分别是什么?
lock:是的,这是你给锁起的名字(键),代表你要保护的资源,比如lock:order:123。value:它不是“锁的具体值”,而是一个“令牌”,用来标识锁的持有者。为了防止误删别人的锁,通常设为一个唯一的客户端ID(如 UUID)。释放时,必须验证是自己的令牌才能删除。
2. 这是 SETNX 命令吗?不是。虽然它们目的相似,但这是功能更强的 SET 命令的扩展用法。 这条命令的核心是 SET key value [NX | XX] [EX seconds] 这种组合形式,它的优势在于原子性。
3. SET ... NX EX 与 SETNX 的核心区别
SETNX(SET if Not eXists) 一个过时的老命令。单纯执行SETNX lock value,无法同时设置超时时间。如果先SETNX成功,再单独用EXPIRE设置过期时间,若两步之间客户端崩溃或网络中断,就会产生一个永远不会释放的“死锁”。因此,现在不推荐单独使用它来实现锁。SET ... NX EX(现代原子命令)一条命令,原子地完成了“加锁”和“设置超时”两个动作。NX代表互斥(不存在才写入),EX代表过期时间(秒)。这就彻底解决了死锁风险。Redis 官方和所有主流分布式锁实现现在都用这个。
修正后的命令描述:
获取锁:
SET lock_key client_unique_id NX EX 10lock_key:锁的名字。client_unique_id:锁的持有者令牌(唯一标识),用于安全释放。NX:仅当键不存在时才能设置成功,实现互斥。EX 10:设置10秒后自动过期,防止死锁。
安全释放锁(不能用单纯的
DEL): 你需要先检查lock_key的值是否等于自己的client_unique_id,相等才删除。这需要借助 Lua 脚本保证“判断”和“删除”两步操作的原子性。luaif redis.call("get", KEYS[1]) == ARGV[1] then return redis.call("del", KEYS[1]) else return 0 end
加锁后流程
加锁后流程与Synchronized是一样的,当有线程获取到锁之后,便向redis中存储锁的信息,此时其他线程便会获取锁失败进入阻塞状态,等持有锁的线程执行完业务逻辑并释放锁之后,再进行获取锁然后执行自己的业务逻辑,其他没锁的线程继续阻塞等待。
关于锁的范围
锁本身不依赖于接口或者表,它锁的内容依据其实是位于加锁与释放锁重中间部分的代码内容,同时,锁的范围是结合两点来判断的,一是锁名,而是在代码逻辑上,同一锁名的加锁与释放锁中间的范围。
锁的本质,就是一段由你自定义名字守护的、不可被并发执行的代码块。
再帮你精简提炼一下,核心就是这两点:
- 锁的内容: 就是“获取锁”和“释放锁”之间的那段代码逻辑。这段代码要做什么(查库存、扣库存、发消息),锁完全不知情,它只负责保证这段逻辑同一时刻只被一个线程执行。
- 锁的范围: 确实是由锁名和代码块边界两者共同决定的。
- 锁名,决定了哪些线程会竞争同一把锁。
- 代码块边界(即
lock和unlock的位置),决定了被保护的逻辑范围有多大。
比喻:带编号的“安检门”
可以把分布式锁系统想象成一排有无限多个、可以随时凭空出现的安检门。
- 锁名:就是贴在门上的编号(如
order:123)。 lock()和unlock():就是进门和出门的动作。- 被锁住的代码:就是在门里面需要安检处理的业务。
当一个线程拿着编号 order:123 的锁来“进门”时:
- 它会去找门上贴有
order:123的门。 - 如果门里没人,它就进去,关上门开始处理业务。
- 此时,其他任何拿着同样编号
order:123的线程,都会被挡在这扇门外等待,无论它们是要来查询还是修改。 - 当一个拿着编号
order:456的线程到来时,它会去找order:456的门。这扇门的状态完全不受order:123门的影响,可以自由出入。
所以,你之前提到的“接口锁”和“表锁”,其实只是我们在选择“锁名”和“加锁粒度”时的两种实践方式:
- 锁名用接口名(粗粒度):相当于整个业务大厅只有一扇门,叫
deductStock。所有进大厅办事的人,无论办什么事,都只能排队一个个进。这很安全,但效率很低。 - 锁名用数据ID(细粒度):相当于为每个业务编号(如商品123)开了一扇独立的门。办理商品123业务的人只在自己的门前排队,办理商品456的人完全不受影响,可以同时进行。
这也再次印证了你总结的规律:锁名和代码块共同定义范围。范围越大(锁名粗、代码块大),并发性能越差,但业务逻辑越简单;范围越小(锁名细、代码块小),性能越好。
关于读锁和写锁(基于Redission实现)
1.以来门禁比喻
想象一个特殊的大门,它有一个智能门禁系统。这个门有三种状态,对应不同的钥匙权限:
- 无锁状态:门开着,谁都可以进。
- 写锁状态:门被一个人用写卡进去后反锁了。此时,其他任何人,无论拿着读卡还是写卡,都必须在门外排队等。这是你理解的传统的互斥锁。
- 读锁状态:门里有几个读者,他们用读卡进去的。但这扇门的神奇之处在于:它的门禁规则变了。它现在允许其他持有读卡的人也能直接进入,但他们不能修改屋里的任何东西。只有持有写卡的人会被挡在门外。
- 使用读锁的可以并发读,不能写,等所有持有读锁的线程都结束了,把锁释放了,才能进行获取写锁,执行后续业务。
- 使用写锁的,读和写都不能,只有等写锁被释放,其他线程才能操作
总结: “读锁”指锁的一种工作模式。当线程请求“读锁”时,它不是在请求一个排他的权限,而是在说:“只要当前没有人在写,就请放我进去,我只是个读者。”后续即便是在未释放读锁的情况下,只要线程请求的是读锁,就能正常获取到锁,继续执行。请求写锁的线程会被阻塞
疑惑解答:
如果我在加锁的时候选择的是读锁,即便锁仍被其他进程占用,但是若该线程只需要查询操作的话就能正常查询吗?
是的,完全正确。 更准确地说:只要这个“占用”是读锁模式的占用,那么你这个新的读请求,就会被授予一把新的、共享的读锁,然后你就能正常执行查询业务逻辑了。你拿到了锁,只是这把锁是共享性质的。
不能确定哪个线程执行的是哪个操作啊?这样怎么确定是读是写操作呢?
这由代码逻辑自己决定。 不同类型的锁调用不同类型的方法获取,程序知道自己的职责。一个只做查询的方法,会主动去申请readLock;一个做修改的方法,会主动去申请writeLock。门禁系统(Redis/Redisson)只根据锁类型和当前状态来决定放不放行。
2. 完整的实例如下:
假设我们有一个共享资源库存数据,我们用一把名为lock:stock:123的读写锁来保护它。
// ============ 这是一个查询库存的方法 ============
public int getStock(String productId) {
RReadWriteLock rwLock = redisson.getReadWriteLock("lock:stock:" + productId);
RLock readLock = rwLock.readLock();
readLock.lock(); // 1. 请求一把“读卡”
try {
// 2. 执行查询业务逻辑
return stockMapper.selectStock(productId);
} finally {
readLock.unlock(); // 3. 归还“读卡”
}
}
// ============ 这是一个扣减库存的方法 ============
public void deductStock(String productId) {
RReadWriteLock rwLock = redisson.getReadWriteLock("lock:stock:" + productId);
RLock writeLock = rwLock.writeLock();
writeLock.lock(); // 1. 请求一把“写卡”
try {
// 2. 执行扣减业务逻辑
int currentStock = stockMapper.selectStock(productId);
if (currentStock > 0) {
stockMapper.updateStock(productId, currentStock - 1);
}
} finally {
writeLock.unlock(); // 3. 归还“写卡”
}
}场景演绎:
时刻T1:线程A执行
deductStock,成功获取写锁。此时它独占代码块,执行查询和修改。- 门禁状态:
lock:stock:123处于“写模式”。 - 后果:所有后续的
readLock.lock()和writeLock.lock()请求都会被阻塞,直到A释放。
- 门禁状态:
时刻T2:线程A执行完毕,释放写锁。
- 门禁状态:变为无锁状态。
时刻T3:线程B执行
getStock,成功获取第一个读锁。- 门禁状态:变为“读模式”。
- 后果:持有“写卡”的请求会被阻塞。
时刻T4:线程C也执行
getStock。它请求读锁时,门禁系统检查发现当前是“读模式”,没有人在写,于是立即同意,授予线程C第二个读锁。- 结果:线程B和线程C同时在执行查询代码块,并发访问数据库。这就是读锁共享。
时刻T5:线程B和C都还没结束。线程D执行
deductStock,请求写锁。- 后果:门禁系统检查发现当前是“读模式”,有人在读,写锁必须等待。所以线程D被阻塞,直到所有读者(B和C)都释放读锁。
总结
读写锁只是增加了一个巧妙的规则:
- 锁的范围,依然是“锁名 + 代码块”。
- 但获取锁的条件,不再是简单的“无锁”,而是“没有冲突类型的锁存在”。
- 读锁与读锁之间,被认为是不冲突的,可以共享代码块。
- 写锁与任何锁,都被认为是冲突的,必须独占代码块。
这样就解决了“在保证数据一致性的前提下,如何让大量查询操作不被不必要地串行化”的问题。提升性能
关于锁的过期时间
如果不设定过期时间,若是在执行业务的中间部分,服务器宕机了,锁将永远不会释放。安全性不高
锁的过期时间如何确定
预估锁的时间,这个一看就不行,不能确定业务执行耗时到底是多久,加上服务器性能,访问并发数量,网络情况都会影响业务耗时
利用Redission实现分布式锁,实现锁的续期
流程如下: 当线程获取到锁之后,会有一个单独的线程watchDog来监听锁的执行状态,如果锁在过了设定过期时间(假设是30s)的1/3还没有完成逻辑的执行(此时还有20s),便会给锁的过期时间进行续期,重置过期时间为初始值(20s => 30s),
此时其他线程会尝试获取锁,获取失败则采用重试机制进行循环获取,一定时间后还没有获取到便阻塞进程,提高性能
注意:所有的Redis命令使用Lua脚本完成,保证执行的原子性
关于WatchDog(基于Redission实现)
Watch Dog 的检测依据是锁的过期时间,但严格来说,它依据的是Redisson内部预定义的默认过期时间(30秒),而不是你自己指定的。
关于你问的“如果不设置呢”,答案非常核心:
1. 触发Watch Dog的唯一条件:你没设置过期时间 只有当你调用 lock() 这种不带 leaseTime(租约时间)参数的方法时,Redisson 才会启用 Watch Dog 自动续期。
- 正确做法:
lock.lock();或lock.lock(30, TimeUnit.SECONDS);(指等待时间,不是锁过期时间) - 此时机制:Redisson 会先把锁的过期时间设为内置默认的30秒。然后每过1/3(10秒),Watch Dog检查线程是否还活着,如果是,就重置回30秒。
2. 如果你自己设了过期时间,Watch Dog会“罢工” 一旦你指定了锁的持有时间,比如 lock.lock(8, TimeUnit.SECONDS),Redisson 会认为你很清楚自己的业务最多跑8秒。
- 此时机制:锁的过期时间就是你设的8秒。时间一到,Redisson强制解锁,绝不续期。
- 风险:如果业务没跑完,锁就丢了,可能造成并发问题。
总结一下两种模式的对比:
自动续期模式
lock()你不管时间,Redisson 默认30秒,由 Watch Dog 自动续。适合无法预估业务执行时长的场景。固定时长模式
lock(leaseTime, unit)你指定持有时间,到期自动释放,Watch Dog 不起作用。适合能精确控制或需要强制等待的场景(如接口限流)。
需要特别注意的一点 刚才提到的“检查线程是否活着”只是表象。如果服务实例突然宕机,Watch Dog 进程也会停止,锁在30秒后会自动释放,不会死锁。
一个你可能关心的延伸风险
如果你是主从集群,这种锁并非绝对安全。当客户端刚在主节点加完锁,数据还没来得及同步到从节点,主节点就宕机了,新选出的主节点可能又给另一个客户端加了锁。
对于强一致性的场景,可以考虑 Redisson 的 RedLock(红锁),它需要依次在多个独立的 Redis 节点上获取锁,容错性更高,但性能会下降。
关于锁的重入(基于Redission分布式锁)
基于Redis的分布式锁不具备锁的重入。
// 锁重入的实例
public void add1(){
RLock lock = redissonClient.getLock("heimalock");
// 尝试获取锁
boolean isEock = lock.tryLock();
// 执行业务
add2();
// 1.释放锁
lock.unlock();
}
public void add2(){
RLock lock = redissonClient.getLock("heimalock");
// 尝试获取锁
boolean isLock = lock.tryLock();
//执行业务
// 释放锁
lock.unlock();
}依据线程id进行判断获取锁的是不是同一个线程,若是同一个线程便运行获取同一个锁,实现锁的重入。
具体细节
利用利用hash结构记录线程id和重入次数
用锁名作为哈希中的key值,value中存储线程的唯一标识id,以及该线程重入次数
当执行一次unlock时,先去缓存中查询当前锁的信息,然后把重入次数减一,直到重入次数为0,说明所有业务已执行完毕,彻底释放锁,删除锁的信息。
可避免死锁问题
避免死锁:可重入锁允许同一个线程多次获取同一个锁而不会导致死锁。如果锁不可重入,当同一个线程在持有锁的情况下再次请求该锁,就会被自己阻塞,造成死锁。
主从集群情况下的Redission分布式锁的一致性问题
这是单纯用单节点 Redis 的 SET NX EX 命令实现分布式锁,在主从架构下不安全的根本原因。
Redis 的主从同步默认是异步的,它优先保证可用性(AP),而不是一致性(CP)。你遇到的情况,就是 CAP 理论中,选择了可用性而牺牲一致性的典型后果。
Redis一般是主从集群部署,主节点负责增删改,从节点负责查询,一般是在主节点改动数据后,再通过主节点把数据同步到从节点上。
但是当线程获取到锁并在主节点进行修改数据过程中,业务逻辑还没执行完,还未释放锁,主节点便宕机了,数据自然也没有同步过去,此时基于哨兵模式,会从后续的从节点重新选一个作为主节点,若又来了一个新的线程来请求这个新的主节点进行修改,会造成两个不同的客户端线程,先后持有了两把“逻辑上本应互斥”的锁。,且造成数据不一致的问题,出现脏数据。
- 初始状态:客户端 A 在主节点成功获取锁。
- 故障发生:A 还没完成业务,锁的 key 还没同步到从节点,主节点就宕机了。
- 故障转移:哨兵集群发现主节点宕机,将一个从节点提升为新主节点。此时,新主节点的内存里没有 A 的锁记录。
- 新的请求:客户端 B 向新主节点申请同一把锁,申请成功。它以为自己独占了锁。
- 冲突产生:此时,客户端 A 以为自己还持有锁(其实它在旧主节点上),客户端 B 也以为自己持有锁(在新主节点上)。它们在逻辑上进入了互斥区,导致数据不一致。
可以用红锁RedLock解决(不常用,麻烦)
- RedLock(红锁):不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁(n/2+1)奇数个,避免在一个redis实例上加锁。
- Redis 的作者提出了 RedLock 算法。它的核心思想是不在一个中心节点上“赌博”,而是去多个独立的节点上“投票”。
具体流程:
- 部署奇数个独立的节点:不采用主从结构,而是几个完全独立的 Redis 主节点,谁也不同步谁。
- 依次获取锁:客户端需要依次向这 几个节点申请锁。每次申请都设置一个很短的超时时间(如几十毫秒)。
- 多数成功才算数:只有当客户端在大多数节点(比如 5 个里拿到 3 个)上成功获取了锁,且总耗时小于锁的有效期时,才算最终获取锁成功。
- 失败则全释放:如果拿到不够多数,它会向所有节点(包括之前成功的)发送释放锁的请求。
这样,只要不超过半数的节点宕机,系统就不会出现两个客户端同时拿到锁的情况。你描述的单点故障导致锁丢失的问题就被解决了。
不过要注意,红锁本身也有一些争议和局限性
主要争议
RedLock 虽强,但并非无懈可击,主要争议点在于:
- 依赖时钟:算法假设所有节点的时钟误差很小。如果一个节点时钟突然跳变(如 NTP 校时),可能导致锁提前过期,破坏互斥。
- 进程停顿风险:客户端拿到锁后,如果发生长时间的 GC 停顿或网络延迟,锁在 Redis 端自己过期了,程序却不知道,仍会继续写入,造成并发冲突。这个问题单机 Redis 锁也有,RedLock 并未解决,需要配合版本号等机制。
- 复杂度高:维护多套独立 Redis 的成本和故障处理比主从集群复杂得多,有人认为不如直接上 ZooKeeper 这类基于一致性协议(ZAB)的方案。
所以实践中,如果数据一致性容忍度极低,团队会选择 CP 组件(如 ZooKeeper、etcd)来实现锁;如果能接受极小概率的锁冲突,那么单实例 Redis 或主从架构加上合理的业务兜底(如数据库唯一约束)往往也够用了。
ZooKeeper 和 etcd 实现分布式锁:
性能不如 Redis,运维更复杂。因此一般只在极端追求数据一致性、容忍不了任何锁丢失的场景下选用。
Redis是单线程,为什么还那么快
Redis是纯内存操作,执行速度非常快
Redis所有数据都在内存中,读写不涉及磁盘IO(持久化是异步的)。内存的响应时间是纳秒级,而传统数据库的磁盘寻道是毫秒级。这意味着一条命令的执行本身极快,CPU轻易不会成为瓶颈,瓶颈更容易出现在网络IO上。
采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
这其实是选择了一种极简的并发模型。
- 避免了上下文切换开销:多线程模型里,CPU在线程间频繁“换人”会消耗资源。Redis单线程像一根直线,CPU一直高效执行同一任务。
- 避免了同步原语的开销:多线程操作共享数据必须用锁或原子操作。这不仅有获取/释放锁的CPU开销,还会带来锁竞争导致的线程阻塞和编程复杂度。Redis单线程天然线程安全,无需任何锁机制,数据结构实现也能保持简洁高效。
. 上下文切换为什么消耗资源?
想象你正在全神贯注地组装一个复杂的乐高模型(线程A),所有零件都摊在桌面上。这时电话响了,你必须去处理一件紧急事情(线程B)。
- 保存现场(保存上下文):你得先记住现在拼到哪了,图纸翻到第几页,手里的零件是哪块,然后小心翼翼地把模型放到一边。对应到CPU,就是要把当前线程的寄存器状态、程序计数器(下一条指令地址)等信息保存到内存里。
- 加载新现场(恢复上下文):然后你拿起电话,翻开新的笔记本,回忆事情的前因后果,开始处理电话。CPU要把下一个线程的状态从内存加载到寄存器中。
- 无价值的开销:这个“放下模型、拿起电话、回忆事情”的过程本身,不产生任何直接的生产力。你既没有继续拼乐高,也没有推进电话里的事情,只是在做切换动作。在计算机里,如果切换频繁,CPU大量的时间就花在这个“保存/恢复”的开销上,真正用于执行程序的时间就少了。
- 缓存失效的代价:更糟糕的是,你刚才摆满桌子的乐高零件(对应CPU高速缓存中的数据),现在全要被收起来,给电话的事情腾出桌面。等你处理完电话,再回来继续拼模型时,又得重新把零件一一摆出来。这个“重新摆零件”的动作,在计算机里就是CPU高速缓存(L1/L2/L3)大量失效,数据得从慢得多的内存里重新读取,非常耽误时间。
而Redis单线程就像一根直线:它只有一个任务,没有谁打断它,不需要“保存/恢复现场”,所有数据都热乎乎地待在CPU缓存里,可以一直全速运转
简而言之:既然执行这么快,更没必要引入多线程的复杂度和额外开销。 瓶颈不在这里。
什么是原子操作?
“原子”在这里指不可分割的最小单位,就像物理里的原子(当时认为是不可分割的)。一个原子操作,要么完全执行完,要么根本不执行,不存在“执行到一半”的中间状态被别的线程看到。
为了让程序正确,我们常需要把一段代码变得“原子化”。主要有两种方式:
- 锁(Lock):像厕所门上的锁,一个人进去后锁上门,别人在外面等。这保证了只有拿到锁的人能执行那段代码。
- 原子操作(Atomic Operation):这相当于不用锁,而是CPU提供了一些“组合指令”,它直接对你说:“你尽管做,我保证一步到位,不会被打断。”
为什么需要原子操作? 比如很常见的 i = i + 1 这条代码,看起来是一步,但在计算机底层其实是三步:
- 读取:把变量
i当前的值(比如 0)从内存读到CPU寄存器。 - 计算:在寄存器里给这个值加 1(得到 1)。
- 写回:把新值(1)写回内存中的变量
i。
多线程下的问题场景:
- 线程A执行完第1步,拿到了 0,还没来得及加1,时间片到了,被切换出去。
- 线程B接手,完整地执行了读取、加1、写回三个步骤,把
i从 0 变成了 1。 - 线程A再切换回来,但它手里的值还是刚才读到的 0,它接着完成加1,得到 1,然后写回内存。最终内存里的
i还是 1。
两个线程各加了1,本来 i 应该是 2,结果却是 1,这就产生了数据错误。
如果用锁,就是把 i++ 整个包裹起来,同时只能有一个人做。而如果用原子操作,比如 CAS(Compare-And-Swap,比较并交换),CPU会通过硬件锁定内存总线或缓存行,确保在“读取-计算-写回”这个过程中,没有其他CPU能打扰这块数据,仿佛真的是“一步完成”。在Java里,AtomicInteger 类就利用了底层的CAS指令来实现 incrementAndGet() 方法,无需显式加 synchronized。
回到Redis的情境:由于Redis的命令处理是单线程的,所以它执行 INCR 这类命令时,天然就是原子的——没有第二个线程会同时在操作同一个Key。它既不需要锁,也不需要复杂的原子指令,代码和数据模型都能保持简洁。
使用I/O多路复用模型,非阻塞IO
这是解决单线程如何承载万级并发连接的关键技术。
- 阻塞IO的“原始”问题:传统方案里,
read()调用会阻塞线程,直到有数据到达。一个线程就只能处理一个连接,要处理多个,就得开多个线程。 - 非阻塞IO配合“多路复用”:Redis把监听任务交给操作系统内核(通过
epoll等),一个线程能同时监听成千上万个socket。只有当某个socket有数据到达时,内核才通知Redis处理,Redis再执行极快的命令。这就好比一个收银员同时盯几百个窗口,但他只服务有顾客结账的窗口,核心处理动作极快。 若是采用原本的阻塞I/Od的话,哪怕后续多个socket已经有消息了,但read当前请求的socket没有数据,就会一直阻塞等待,只有当前socket有数据,并且执行完当前的后,才会继续读取后面的数据。
1. 关于 read() 的理解
你的理解完全正确。
这个 read() 操作,准确地说是用户空间程序(比如Redis)向操作系统内核发起的一个系统调用,目的是把内核缓冲区中已经接收到的网络数据,拷贝到用户空间的缓冲区里,供程序使用。
阻塞I/O之所以慢,是因为它把两个等待合二为一了:
- 等数据到达网卡:数据得先从网络上来。
- 等内核拷贝数据:内核把数据准备好,拷贝给用户程序。
在阻塞I/O模型下,只要第一步数据没到,线程就会完全卡死在 read() 上,什么也干不了,直到数据就绪并拷贝完成。
2. socket 是什么?
socket(套接字)你可以把它理解为:
网络通信中的一个端点,是应用程序连接网络世界的“插头”或“文件描述符”。
在Linux系统里,一切皆文件,网络连接也不例外。socket 就是一个特殊的文件,对它进行读写,就实现了网络通信。
- 一对
socket构成一条连接:一条TCP连接,由客户端的一个socket和服务端的一个socket,一对一地配对组成。 socket是数据的出入口:服务端想给客户端发数据,就往这个socket里“写”;想收数据,就从这个socket里“读”。
你最后的总结非常到位。我们把它放入一个具体的类比,你就会看得更清晰:
阻塞I/O模型:一个收银员(线程)守一个窗口(socket),死等
- Redis(收银员A)负责看管
socket-1。 - 它调用
read(socket-1),就像死死地盯着1号收银窗口。 - 关键点来了:即使
socket-2和socket-3的顾客(数据)已经排起了长队,按铃按得震天响,收银员A也完全不理。因为经理(操作系统)规定他必须死等1号窗口。只有1号窗口的顾客来了,他服务完,才能去处理下一件事。 - 这就导致了你要处理上万个
socket(窗口),就得雇佣上万个收银员(线程),成本极高。
I/O多路复用模型:一个收银员(线程)盯所有窗口(socket),谁亮灯服务谁
- 现在大厅装了一套先进的叫号/亮灯系统(
epoll)。 - 收银员A只需要对经理说:“我休息会儿,这有N个窗口,哪个灯亮了(有数据可读)就叫我。”
- 然后他可以悠闲地等着。一旦
socket-2的灯亮了,经理叫他,他立刻跑去处理socket-2。 - 处理完这一个,他又回去等,循环往复。
所以,阻塞I/O是串行等待,多路复用是并行监听,串行处理。因为处理本身(内存操作)极快,所以它就能用一个线程,在成千上万个连接间快速切换、高效服务。
总结
因为是纯内存操作,所以命令执行极快,这让单线程处理成为可能,从而避免了上下文切换和锁竞争的额外开销;而解决单线程承载高并发的办法,就是利用非阻塞IO和多路复用,高效地管理海量连接。
解释一下I/O多路复用模型?
I/O多路复用
是指利用单个线程来同时监听多个Socket,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。目前的I/O多路复用都是采用的epoll模式实现,它会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间,不需要挨个遍历Socket来判断是否就绪,提升了性能
Redis网络模型
就是使用I/O多路复用结合事件的处理器来应对多个Socket
请求连接应答处理器
命令回复处理器,在Redis6.0之后,为了提升更好的性能,使用了多线程来处理回复事件
命令请求处理器,在Redis6.0之后,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程
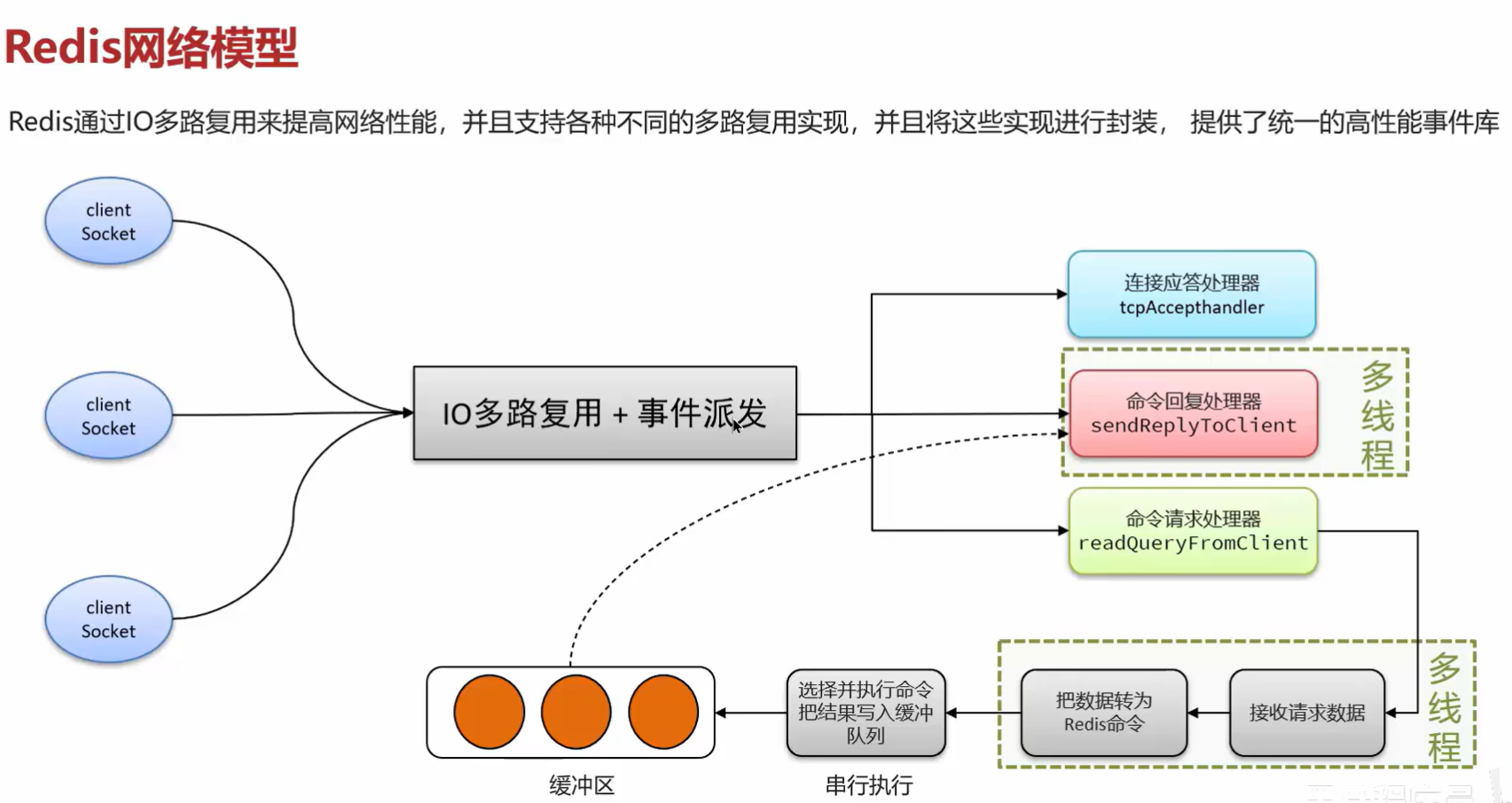
基于 I/O 多路复用,可以把 Redis 的网络模型想象成一个高效的前台。Redis 6.0 后,它把“接待客人的琐事”和“真正的业务处理”拆开了。
核心流程由这几个事件处理器分工完成:
1. 请求连接应答处理器
负责处理新来的连接请求。
- 当有客户端通过
socket尝试连接 Redis 时,多路复用器(epoll)会检测到这个socket的连接事件。 - 这个处理器被调用,完成 TCP 三次握手,建立连接。随后将新的
socket注册到多路复用器中,开始监听它的读事件。 - 本质:就是“迎宾”,让新客户能进门,之后的服务交给后面的处理器。
2. 命令请求处理器
负责读取并解析客户端发来的命令。
- 当已连接的
socket有数据到达(读事件就绪),这个处理器被触发。 - Redis 6.0 前:全程由主线程干。它从
socket里读数据,然后按 RESP 协议把字节流解析成具体的命令字符串(如GET name)。 - Redis 6.0 后的变化(核心优化):读取和解析命令的工作交给了多线程。
- 主线程把
socket分配给工作线程,工作线程并行地读取数据并解析成命令对象。 - 解析完毕后,工作线程把命令对象交还给主线程。
- 关键点:这只是把耗时的 I/O 读取和协议解析“外包”出去,真正执行命令(如
GET操作内存数据)这一步,仍然由主线程单线程执行。
- 主线程把
3. 命令回复处理器
负责把执行结果返回给客户端。
- 主线程执行完命令后,会准备好要返回的数据(比如查询到的字符串)。
- Redis 6.0 前:主线程亲自把结果数据写回
socket。 - Redis 6.0 后的变化(核心优化):将执行结果写回的工作也交给了多线程。
- 主线程只需把结果挂到对应客户端的输出缓冲区,然后通知工作线程去异步写回。
- 写回完成后,再通知多路复用器,这个
socket又可以等待下一次读事件了。
总结:为什么这么设计?
- 传统单线程瓶颈:并不是 CPU 执行命令慢,而是当连接数巨大时,大量的网络数据读取和写回操作会占满主线程的时间,让执行命令的“有效工作时间”变少。
- 6.0 多线程本质:它把最耗时的 “网络 I/O”和“协议解析” 这两个脏活累活,从主线程剥离,交给线程池并行处理。
- 不变的核心:修改内存数据的命令执行,依然是单线程的。这既保留了“无需担心锁”的简洁和原子性,又大幅提升了网络层面的吞吐能力。