复杂度分析
时间复杂度
时间复杂度分析:评估代码耗时大小
大O表示法:不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势
当n很大时,公式中的低阶,常量,系数三部分并不左右其增长趋势,因此可以忽略,我们只需要记录一个最大的量级就可以了
| 描述 | 表示形式 |
|---|---|
| 常数 | O(1) |
| 对数 | O(log n) |
| 线性 | O(n) |
| 线性对数 | O(n * log n) |
| 平方 | O(n^2) |
| 立方 | O(n^2) |
| k次方 | O (n^k) |
| 指数 | O(2^n) |
| 阶乘 | O(n!) |
速记口诀:常对幂指阶
- 复杂度分析就是要弄清楚代码的执行次数和数据规模n之间的关系
- 只要代码的执行时间不随着n的增大而增大,这样的代码复杂度都是O(1)
- 当n很大时,公式中的低阶,常量,系数三部分并不左右其增长趋势,因此可以忽略,我们只需要记录一个最大的量级就可以了
空间复杂度
空间复杂度全称是渐进空间复杂度,表示算法占用的额外存储空间与数据规模之间的增长关系
一般说复杂度就是指的时间复杂度
时间复杂度和空间复杂度详解
这两个概念是算法效率分析的基石,用来衡量一个算法执行时对时间和内存的消耗。
一、大 O 表示法(Big O Notation)
我们通常用 大 O 表示法 来描述复杂度,它表示算法运行时间或内存使用随输入规模增长的增长趋势,忽略常数项和低阶项。
- O(1) :常数级,不随输入规模变化
- O(log n):对数级,非常高效
- O(n) :线性级,与输入大小成正比
- O(n log n):常见于排序算法
- O(n²) :平方级,双重循环
- O(2ⁿ) :指数级,极慢
二、时间复杂度
定义:算法运行所需时间与输入数据规模之间的关系。
举例说明
1. O(1) – 常数时间
无论输入多大,只执行固定次数的操作。
public int getFirstElement(int[] arr) {
return arr[0]; // 只做一次数组访问
}2. O(n) – 线性时间
循环次数与输入规模 n 成正比。
public int findMax(int[] arr) {
int max = arr[0];
for (int i = 1; i < arr.length; i++) { // 循环 n-1 次
if (arr[i] > max) {
max = arr[i];
}
}
return max;
}3. O(n²) – 平方时间
双重循环,内外层都与 n 成正比。
public void bubbleSort(int[] arr) {
int n = arr.length;
for (int i = 0; i < n - 1; i++) { // 外层 n 次
for (int j = 0; j < n - i - 1; j++) { // 内层约 n/2 次
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}4. O(log n) – 对数时间
每次迭代将问题规模减半(典型:二分查找)。
public int binarySearch(int[] arr, int target) {
int left = 0, right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1; // 排除右半
} else {
right = mid - 1; // 排除左半
}
}
return -1;
}- 每次循环将搜索范围减半,2^k = n → k = log₂ n
5. O(n log n) – 线性对数时间
常见于归并排序、快速排序(平均情况)。
public void mergeSort(int[] arr, int left, int right) {
if (left < right) {
int mid = left + (right - left) / 2;
mergeSort(arr, left, mid); // 递归 O(log n) 层
mergeSort(arr, mid + 1, right);
merge(arr, left, mid, right); // 每层合并 O(n)
}
}
// 合并部分省略,总复杂度 O(n log n)6. O(2ⁿ) – 指数时间
递归解决子集、斐波那契(朴素递归)。
java
public int fib(int n) {
if (n <= 1) return n;
return fib(n - 1) + fib(n - 2); // 每个调用分裂成两个
}三、空间复杂度
算法运行过程中额外占用的内存与输入规模之间的关系(不包含输入本身占用的空间)
常见情况
1. O(1) – 常数空间
只使用固定数量的额外变量,不随输入规模增长。
public int sum(int[] arr) {
int total = 0; // 1个变量
for (int num : arr) {
total += num;
}
return total;
}2. O(n) – 线性空间
需要额外存储与输入大小成正比的容器,需要额外的数组或列表,长度与输入规模成正比。
public int[] copyArray(int[] arr) {
int[] newArr = new int[arr.length]; // 额外数组,长度 n
for (int i = 0; i < arr.length; i++) {
newArr[i] = arr[i];
}
return newArr;
}3. O(n²) – 平方空间
常见于动态规划中的二维表格。
public int[][] createMatrix(int n) {
int[][] matrix = new int[n][n]; // n × n 大小的矩阵
return matrix;
}def create_matrix(n):
matrix = [[0]*n for _ in range(n)] # n×n 大小
return matrix4. 递归栈空间(重要!)
递归调用会消耗调用栈内存。
// 空间复杂度 O(n) 因为递归深度为 n
public int factorial(int n) {
if (n <= 1) return 1;
return n * factorial(n - 1);
}注意:递归的空间复杂度通常等于最大递归深度。
注意区分
- 输入本身占用的空间(如传入的数组)通常不计入算法的空间复杂度,我们只关心额外分配的空间。
- 递归调用会消耗调用栈空间。例如递归深度为 n 的斐波那契函数,空间复杂度为 O(n)。
四、用一张表速查
| 复杂度 | 名称 | 例子 | 数据规模 10⁶ 时的操作次数 |
|---|---|---|---|
| O(1) | 常数 | 数组索引 | 1 |
| O(log n) | 对数 | 二分查找 | ~20 |
| O(n) | 线性 | 简单查找 | 1,000,000 |
| O(n log n) | 线性对数 | 归并排序 | ~20,000,000 |
| O(n²) | 平方 | 冒泡排序 | 1,000,000,000,000 |
| O(2ⁿ) | 指数 | 递归求子集 | 天文数字 |
五、实践建议
- 先保证正确,再优化复杂度。
- 权衡时间与空间:有时可以用 O(n) 空间换取 O(1) 时间(如使用哈希表加速查找)。
- 递归改迭代:可降低栈空间开销。
- 实际测试:复杂度只是理论分析,小数据量下常数因子也很重要。
如果你有具体算法想分析复杂度,可以把代码发给我,我帮你拆解。
集合篇
数组
数组(Array)是一种用连续的内存空间存储相同数据类型数据的线性数据结构。
依据索引获取值,创建数组时,先去堆内存中开辟一段连续的内存空间,作为存储数据的地方,栈内存则存储定义的数组名array,指向数组的首地址。
查找数据时,依据寻址公式来查找需要的数据:
寻址公式:a[i] = baseAddress(数组首地址) + i * dataTypeSize(存储的单个变量所占内存大小)
- **baseAddress:**数组的首地址
- dataTypeSize:代表数组中元素类型的大小,int型的数据,dataTypeSize = 4个字节
数组不使用1开始而是从0开始是因为,若是从1开始,进行寻址时,寻址公式就要多一次减法操作,效率不如从零开始。
操作数组的时间复杂度(查找)
随机查询(根据索引查询)
数组元素的访问是通过下标来访问的,计算机通过数组的首地址和寻址公式能够很快速的找到想要访问的元素 O(1)
未知索引查询
情况一:查找数组内的元素,查找55号数据 挨个遍历对比 O(n)
情况二:查找排序后的数组内元素,二分查找55号数据 O(logn)
操作数组的时间复杂度 (插入、删除)
数组是一段连续的内存空间,因此为了保证数组的连续性会使得数组的插入和删除的效率变的很低。一般都是O(n)除非特殊的首尾插入,但是平均下来都是O(n)
数组与List的区别
在 Java 中,数组(Array) 和 List(接口,常用实现类如 ArrayList) 是两种不同的数据结构,它们在许多方面有本质区别。
一、核心区别速查表
| 特性 | 数组 (Array) | List (以 ArrayList 为例) |
|---|---|---|
| 大小 | 固定长度,创建后不可变 | 动态可变,可自动扩容 |
| 类型安全 | 编译时检查,支持协变 | 泛型,编译时严格检查 |
| 存储元素 | 基本类型 + 对象 | 只能存对象(基本类型需包装类) |
| 性能 | 访问更快,内存更紧凑 | 稍慢(涉及方法调用、动态扩容) |
| 提供的方法 | 仅有 length 属性 | 丰富的方法(add, remove, contains, indexOf 等) |
是否实现 Iterable | 否(但可用增强 for 循环) | 是 |
| 维度 | 支持多维(如 int[][]) | 可嵌套实现多维(List<List<Integer>>) |
二、代码示例对比
1. 长度是否可变
// 数组:长度固定
int[] arr = new int[3];
arr[0] = 1; // 可以修改元素
// arr[3] = 4; // 编译通过,运行报错 ArrayIndexOutOfBoundsException
// ArrayList:动态扩容
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4); // 自动扩容,不会报错2. 存储基本类型的差异
// 数组可以直接存基本类型
int[] arr = {1, 2, 3};
// List 必须使用包装类(自动装箱)
List<Integer> list = new ArrayList<>();
list.add(1); // 自动装箱:int → Integer
// 如果尝试 List<int> 会编译错误3. 提供的操作方法
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.remove(0);
System.out.println(list.contains("B")); // true
System.out.println(list.size()); // 1
list.clear();
// 数组没有这些便捷方法,需手动实现
String[] arr = {"A", "B"};
// 没有 remove 方法,只能新建数组或借助集合4. 遍历方式
// 两者都支持普通 for 和增强 for
int[] arr = {1,2,3};
for (int num : arr) { }
List<Integer> list = Arrays.asList(1,2,3);
for (int num : list) { }
// List 还可以使用 Iterator
Iterator<Integer> it = list.iterator();
while (it.hasNext()) { }5. 类型协变与泛型
// 数组是协变的
Number[] numArr = new Integer[10]; // 编译通过
// List 不是协变的(泛型不变)
List<Number> numList = new ArrayList<Integer>(); // 编译错误
List<? extends Number> wildList = new ArrayList<Integer>(); // 通配符可以三、性能对比
- 访问元素:数组通过索引直接访问 O(1),
ArrayList.get(index)也是 O(1),但多了一次方法调用。 - 内存占用:数组更紧凑,
ArrayList封装了数组并维护 size 字段,额外开销。 - 扩容成本:
ArrayList扩容时(默认1.5倍)会创建新数组并复制旧数据,若频繁添加大量元素,可能影响性能。可提前用ensureCapacity()优化。
四、什么时候用数组,什么时候用 List?
推荐使用 List 的情况:
- 需要动态添加/删除元素
- 需要调用集合框架提供的方法(如
contains、remove、subList) - 代码需要更好的可读性和可维护性
- 与泛型、集合框架其他部分(如
Stream)交互
可以考虑使用数组的情况:
- 元素数量固定不变
- 性能敏感的核心代码(如底层计算、高频访问)
- 需要存储基本类型且避免装箱带来的内存开销
- 多维数组(
int[][])比List<List<Integer>>更直观
五、它们之间的转换
// 数组 → List
String[] arr = {"a", "b"};
List<String> list1 = Arrays.asList(arr); // 注意:返回的List是固定大小的,不能add/remove
List<String> list2 = new ArrayList<>(Arrays.asList(arr)); // 真正的ArrayList
// List → 数组
List<String> list = new ArrayList<>();
list.add("a");
String[] arr2 = list.toArray(new String[0]); // 推荐
String[] arr3 = list.toArray(new String[list.size()]); // 也常用总结
- 数组:定长、可存基本类型、性能略优、语法简单。
- List(ArrayList):变长、只能存对象、功能丰富、更灵活。
日常开发中,除非有特殊的性能或内存要求,优先使用 List(如 ArrayList),因为它能让你更安全、更高效地处理集合数据。
ArrayList源码分析(jdk8)
ArrayList中的成员变量
/**
*默认初始的容量
*/
private static final int DEFAULT_CAPACITY=10;
// 用于空实例的共享空数组实例
private static final ObjectOEMPTY_ELEMENTDATA ={};
/**
*用于默认大小的空实例的共享空数组实例。
*我们将其与EMPTY_ELEMENTDATA区分开来,以了解添加第一个元素时要膨胀多少
*/
private static final ObjectDEFAULTCAPACITY_EMPTY_ELEMENTDATA ={};
/**
*存储ArrayList元素的数组缓冲区。ArrayList的容量就是这个数组缓冲区的长度。
*当添加第一个元素时,任何具有elementData==DEFAULTCAPACITY_EMPTY_ELEMENTDATA的空ArrayList
*都将扩展为DEFAULT_CAPACITY
*当前对象不参与序列化
*/
transient Object[] elementData; //non-private to simplify nested class access
/**
*ArrayList的大小(它包含的元素数量)
*@serial
*/
private int size;ArrayList的构造函数
无参构造函数
创建默认大小的空集合
public ArrayList() {
//无参构造函数,默认创建空集
this.elementData =DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}带初始化容量的构造函数
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData =EMPTY_ELEMENTDATA;
} else {
throw new lllegalArgumentException("llegal Capacity: "+initialCapacity);
}
}作用是创建一个带初始化容量的空集合:
- 若是初始化容量大于0,创建初始化大小的集合
- 初始大小等于0,创建空集合返回
- 初始化小于0,抛出异常
形参为Collection<? extends E>的构造函数
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size,Object[].class);
}
}else {
//replace with empty array.
elementData=EMPTY_ELEMENTDATA;
}
}Collection是所有集合的父接口,这里的意思是可以传入所有继承了Collection的单列集合。
作用是:
先把集合转为数组
若数组为空,返回空数组
若数组类型为ArrayList,直接让elementData指向该数组地址(把数组的地址复制给elementData中)
若数组不为ArrayList,则把其中变量使用Arrays.copy拷贝到ArrayList的属性elementData中。
ArrayList添加和扩容操作分析
初始创建
>> 是 Java 中的有符号右移运算符(Signed Right Shift Operator)。
作用
将一个二进制数向右移动指定的位数,左边空出来的位用符号位填充(正数补0,负数补1),移出的低位直接丢弃。
等价数学公式
- 正数:
x >> n≈x / 2ⁿ(向下取整) - 负数:
x >> n≈x / 2ⁿ(向负无穷取整,但实际是向下取整)
public class RightShiftDemo {
public static void main(String[] args) {
// 正数示例
int a = 16; // 二进制: 10000
System.out.println(a >> 2); // 4 (10000 → 100)
// 负数示例
int b = -16; // 二进制补码: ...11110000
System.out.println(b >> 2); // -4
// 实际应用:取平均值防止溢出
int x = 100, y = 200;
int mid = (x + y) >> 1; // (300)/2 = 150
}
}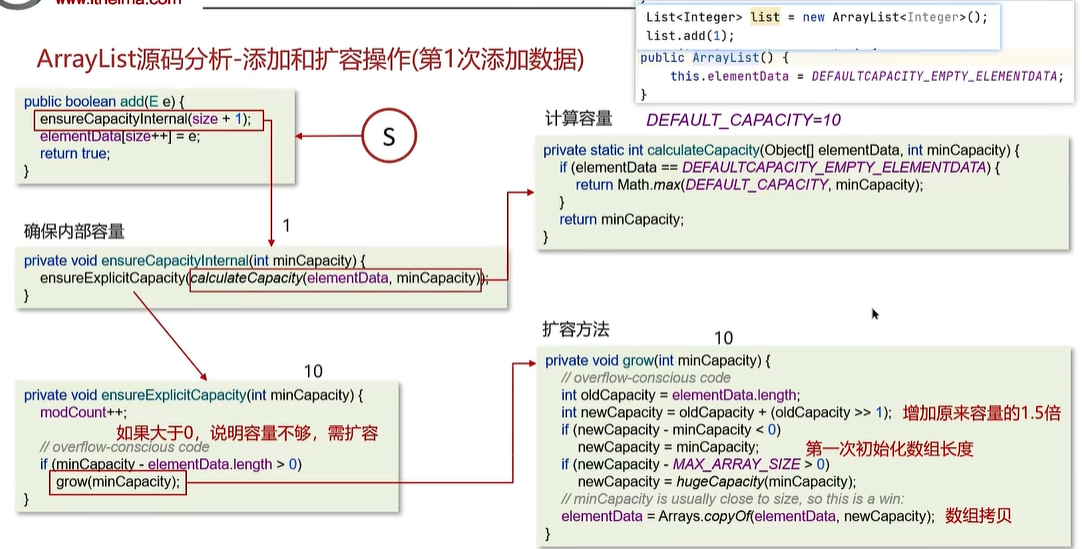
- 初始size为0,数组为空,size加一的到当前数组容量大小
- 传入ensureCapacityInternal中调用calculateCapacity计算容量大小
- 若是添加数据前集合为空,则取默认集合大小(DEFAULT_CAPACITY= 10)与当前集合添加数据后的大小中的最大值,此时就是10和1,容量为10
- 走到ensureExplicitCapacity方法,传入参数为10,此时第一次添加数据,创建默认大小为10的集合,10-0大于0,走扩容方法
- grow扩容方法接收到参数10,旧容量oldCapacity =0,新容量newCapacity = 旧容量大小 + 旧容量 / 2 = 0, 结果满足条件newCapacity -oldCapacity,容量大小设为了传入的minCapacity = 10
第2到第10次添加数据(不需要扩容)
第2以及第10次添加数据时,走到方法ensureExplicitCapacity后,不满足if中的条件,不会进行扩容
- 第10次添加数据,size +1 =添加后的集合大小也就是10,此时走到calculateCapacity中,直接返回添加数据之后的大小10
- 到ensureExplicitCapacity中,集合大小为10,因为第一次添加数据时就设置为大小为10,所以后续只要不触发扩容,集合大小都是10,但是size指的是已经装了几个元素,指的是元素的数量,所以第十次添加size = 9 ,elementData.length = 10,这里并不会触发if中的minCapacity(10)- elementData.length >0,仍不会扩容
第十一次添加数据(扩容)
同样是到ensureExplicityCapacity中,此时minCapacity = 11,ElementData.length = 10,满足扩容条件,进入grow方法进行扩容,传入参数为 minCapacity = 11。
默认扩容大小为1.5倍
ArrayList底层实现原理
- ArrayList底层是用动态的数组实现的
- ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
- ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组(使用右移>>2,会损失部分精度)
- ArrayList在添加数据的时候
- 确保数组已使用长度(size)加1之后足够存下下一个数据
- 计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
- 确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上。
- 返回添加成功布尔值。
ArrayList list=neWArrayList(1O)中的list扩容几次
调用有参构造
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData =EMPTY_ELEMENTDATA;
} else {
throw new lllegalArgumentException("llegal Capacity: "+initialCapacity);
}
}该语句只是声明和实例了一个 ArrayList,指定了容量为10,未扩容
数组和List之间的转换
- 数组转List,使用JDK中java.util.Arrays工具类的asList方法List转数组,
- 使用List的toArray方法。无参toArray方法返回Object数组,传入初始化长度的数组对象,返回该对象数组
- Arrays.asList转换list之后,如果修改了数组的内容,list会受影响,因为它的底层使用的Arays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个内存地址
- list用了toArray转数组后,如果修改了list内容,数组不会影响,当调用了toArray以后,在底层是它是进行了数组的拷贝,跟原来的元素就没啥关系了,所以即使list修改了以后,数组也不受影响
ArrayList与LinkedList的区别
底层数据结构
ArrayList是动态数组的数据结构实现
LinkedList是双向链表的数据结构实现
操作数据效率
- ArrayList按照下标查询的时间复杂度O(1)【内存是连续的,根据寻址公式】,LinkedList不支持下标查询
- 查找(未知索引I):ArrayList需要遍历,链表也需要链表,时间复杂度都是O(n)
- 新增和删除
- ArrayList尾部 插入和删除,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)
- LinkedList头尾节点增删时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
内存空间占用
- ArrayList底层是数组,内存连续,节省内存
- LinkedList 是双向链表需要存储数据,和两个指针,更占用内存
线程安全
ArrayList和LinkedList都不是线程安全的
如果需要保证线程安全,有两种方案:
在方法内使用,局部变量则是线程安全的
使用线程安全的ArrayList和LinkedList
- java
List<Object> syncArrayList = Collections.synchronizedList(new ArrayList<>()); List<Object> syncLinkedList = Collections.synchronizedList(new LinkedList<>());
通过链表实现的集合,一部分保存数据,一部分保存指针,指向下一个数据的地址,若是双向链表,则是互相指向。
双向链表,它支持两个方向 每个结点不止有一个后继指针next指向后面的结点有一个前驱指针prev指向前面的结点
- 只有在查询头节点的时候不需要遍历链表,时间复杂度是O(1)
- 查询其他结点需要遍历链表,时间复杂度是O(n)
- 只有在添加和删除头节点的时候不需要遍历链表,时间复杂度是O(1)
- 添加或删除其他结点需要遍历链表找到对应节点后,才能完成新增或删除节点,时间复杂度是O(n)
- 对比单链表:
- 双向链表需要额外的两个空间来存储后继结点和前驱结点的地址
- 支持双向遍历,这样也带来了双向链表操作的灵活性
二叉树的常见分类
二叉树是每个节点最多有两个子节点的树结构。按不同维度可分为以下几类:
| 分类维度 | 类型 | 特点 |
|---|---|---|
| 节点度限制 | 满二叉树(Full Binary Tree) | 每个节点要么是叶子节点,要么有两个子节点(不存在度为1的节点)。 |
| 完全二叉树(Complete Binary Tree) | 除了最后一层,其余层节点全满,且最后一层节点尽可能靠左排列。堆通常基于完全二叉树实现。 | |
| 完美二叉树(Perfect Binary Tree) | 所有内部节点都有两个子节点,且所有叶子节点在同一层。 | |
| 数值性质 | 二叉搜索树(Binary Search Tree, BST)二叉查找树,有序二叉树或者排序二叉树 | 左子树所有节点值 < 根节点值 < 右子树所有节点值,支持快速查找、插入、删除。 |
| 平衡二叉树(Balanced Binary Tree) | 任意节点的左右子树高度差不超过1(如 AVL 树),保证操作时间复杂度 O(log n)。 | |
| 红黑树(Red-Black Tree) | 一种近似平衡的二叉搜索树,通过颜色标记和旋转维持平衡,TreeMap、HashSet(哈希冲突时)的内部实现。 | |
| 应用场景 | 堆(Heap) | 一种特殊的完全二叉树,分为大顶堆(父节点 ≥ 子节点)和小顶堆(父节点 ≤ 子节点),常用于优先队列。 |
此外,还有线索二叉树(利用空指针指向前驱/后继)、哈夫曼树(最优二叉树,用于编码)等变种。
承接上面的二叉树分类,继续介绍 哈夫曼树 和 线索二叉树。
一、哈夫曼树(Huffman Tree)
1. 是什么?
- 一种带权路径长度最短的二叉树,也称为最优二叉树。
- 叶子节点带有权值(如字符出现频率),构造的目标是让树的带权路径长度(WPL) 最小。
2. 如何构造(哈夫曼算法)?
- 将所有叶子节点按权值放入最小堆(或多次排序)。
- 重复以下步骤直到只剩一个节点:
- 取出权值最小的两个节点作为左右子节点。
- 创建一个新的内部节点,权值为两者之和。
- 将新节点放回堆中。
- 最后剩下的节点就是哈夫曼树的根。
3. 特点
- 没有度为1的节点(即要么是叶子,要么有两个孩子)。
- 权值越大的叶子离根越近,路径越短。
- 每个内部节点都是由两个子节点合并而来。
4. 主要用途
- 数据压缩:如 ZIP、JPEG、MP3 中的哈夫曼编码。
- 为每个字符分配变长编码(频率高的用短码,低的用长码)。
- 编码前缀唯一,不会产生歧义。
- 文件加密、最优归并顺序等。
例如:字符频率 A:5, B:2, C:1, D:1
构建的哈夫曼树可能为:
9
/ \
5 4
/ \
2 2
/ \
C D
A 编码: 0
B 编码: 10
C 编码: 110
D 编码: 111二、线索二叉树(Threaded Binary Tree)
1. 为什么需要线索?
普通二叉树的叶子节点或度为1的节点会有很多 空指针(左右孩子为 null)。遍历(如中序遍历)时需要使用递归或栈,浪费空间且无法从任意节点直接找到前驱/后继。
2. 什么是线索?
- 将那些空指针利用起来,指向该节点在某种遍历顺序下的 前驱 或 后继。
- 这种被利用的指针称为“线索”。
3. 怎么实现?
- 在每个节点中增加两个标志位:
ltag和rtag。ltag = 0表示左孩子指针指向左孩子;ltag = 1表示左指针指向前驱。rtag = 0表示右孩子指针指向右孩子;rtag = 1表示右指针指向后继。
- 通过一次遍历(如中序遍历)将空指针修改为线索。
// 节点结构示例
class ThreadedNode {
int data;
ThreadedNode left, right;
boolean leftIsThread; // true 表示 left 是线索
boolean rightIsThread; // true 表示 right 是线索
}4. 类型
- 中序线索二叉树:最常用,按中序遍历的顺序建立线索。
- 先序线索二叉树、后序线索二叉树。
5. 优点与用途
- 可以线性化地遍历二叉树,不需要递归或栈,节省空间和时间。
- 可以从任意节点出发快速找到遍历顺序下的前驱或后继。
- 常用于需要频繁进行遍历、且树结构不常修改的场景(如编译器中的抽象语法树遍历)。
三、总结对比
| 特性 | 哈夫曼树 | 线索二叉树 |
|---|---|---|
| 核心目标 | 最小化带权路径长度(压缩) | 利用空指针,方便快速找到前驱/后继 |
| 节点性质 | 无度为1的节点 | 普通节点 + 两个标志位 |
| 构造方式 | 贪心算法(每次取最小权值合并) | 基于某次遍历(如中序)修改空指针 |
| 主要应用 | 数据压缩、最优编码 | 高效遍历(免递归/栈)、寻找前驱后继 |
| 是否改变树结构 | 是,完全重建 | 否,只是添加线索(指针重用) |
红黑树的特性
- 性质1:节点要么是红色,要么是黑色
- 性质2:根节点是黑色
- 性质3:叶子节点都是黑色的空节点
- 性质4:红黑树中红色节点的子节点都是黑色
- 性质5:从任一节点到叶子节点的所有路径都包含相同数目的黑色节点
- 一种近似平衡的二叉搜索树,通过颜色标记和旋转维持平衡,
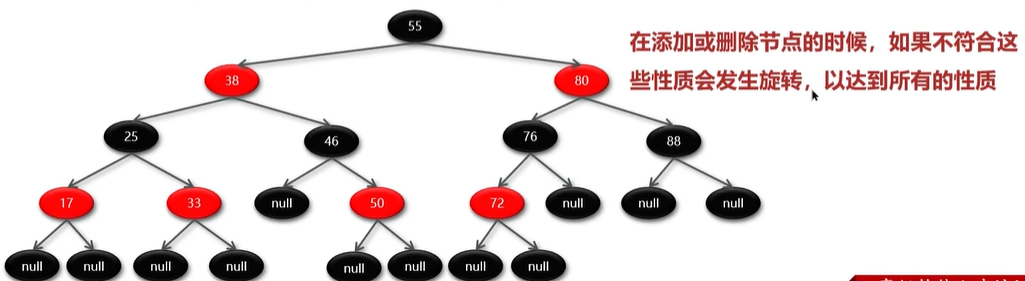
避免特殊情况下二叉树退化为链表一样的结构,达到自平衡的状态
散列表(哈希表)
在HashMap中的最重要的一个数据结构就是散列表,在散列表中又使用到了红黑树和链表
散列表(HashTable)又名哈希表/Hash表,是根据键(Key)直接访问在内存存储位置值(Value)的数据结构,它是由数组演化而来的,利用了数组支持按照下标进行随机访问数据的特性
数组依据下标访问数据,一个下标对应一个数据,散列表(哈希表)的key值相当于数据在数组的下标,一个key对应一个数组中的位置
假设有100个人参加马拉松,不采用1-100的自然数对选手进行编号,编号有一定的规则比如:2023ZHBJ001,其中2023代表年份,ZH代表中国,BJ代表北京,001代表原来的编号,那此时的编号2023ZHBJ001不能直接作为数组的下标,此时应该如何实现呢?
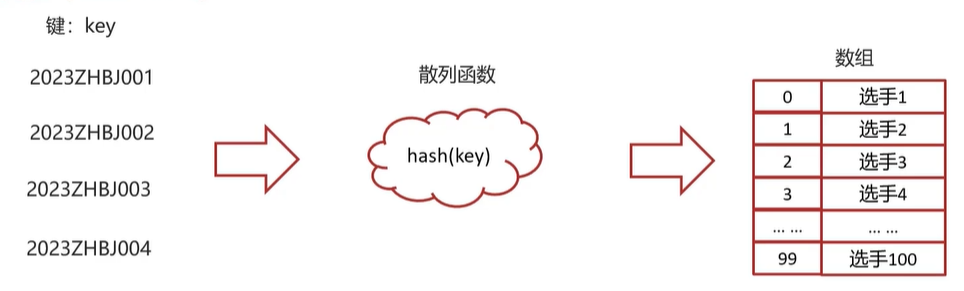
将不规则键(key)映射为数组下标的函数叫做散列函数。可以表示为:hashValue=hash(key)
散列函数的基本要求:
- 散列函数计算得到的散列值必须是大于等于O的正整数,因为hashValue需要作为数组的下标。
- 如果key1==key2,那么经过hash后得到的哈希值也必相同即:hash(key1)==hash(key2)
- 如果key1!=key2,那么经过hash后得到的哈希值也必不相同即:hash(key1)!=hash(key2)
散列冲突(哈希碰撞)
实际的情况下想找一个散列函数能够做到对于不同的key计算得到的散列值都不同几乎是不可能的,即便像著名的MD5,SHA等哈希算法也无法避免这一情况,这就是散列冲突(或者哈希冲突,哈希碰撞,就是指多个key映射到同一个数组下标位置),可使用链表解决
散列冲突-链表法 (拉链)
在散列表中,数组的每个下标位置我们可以称之为桶(bucket)或者槽(slot),每个桶(槽)会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
当查找、删除一个元素时,我们同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除
平均情况下基于链表法解决冲突时查询的时间复杂度是O(1),插入始终为O(1),直接计算哈希值插入即可
散列表可能会退化为链表,查询的时间复杂度就从O(1)退化为O(n)
将链表法中的链表改造为其他高效的动态数据结构,比如红黑树,查询的时间复杂度是 O(logn)
链表的长度大于8且数组长度大于64转换为红黑树
将链表法中的链表改造红黑树还有一个非常重要的原因,可以防止DDos攻击
DDos攻击: 分布式拒绝服务攻击(英文意思是Distributed Denial ofService,简称DDoS) 指处于不同位置的多个攻击者同时向一个或数个目标发动攻击,或者一个攻击者控制了位于不同位置的多台机器并利用这些机器对受害者同时实施攻击。由于攻击的发出点是分布在不同地方的,这类攻击称为分布式拒绝服务攻击,其中的攻击者可以有多个
HashMap实现原理
HashMap的数据结构:底层使用hash表数据结构,即数组和链表或红黑树
HashMap的Put流程
- 当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
- 存储时,如果出现hash值相同的key,此时有两种情况。
- 如果key相同,则覆盖原始值;
- b.如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
- 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
HashMap的Put具体源码流程
- 如果
table == null或长度为 0,执行resize()进行初始化 - 根据键值key计算hash值得到数组索引
- 判断table[i] == nul,条件成立,直接新建节点添加
- 如果table[i] ! = null,不成立
- 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
- 判断table[i]是否为treeNode,即table[i]是否是红黑树,如果是红黑树,则直接在树中插入键值对
- 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,数组长度是否大于64,满足条件则把链表转换为红黑树,在红黑树中执行插入操作,遍历过程中若发现key已经存在直接覆盖value
- 插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
HashMap的扩容原理
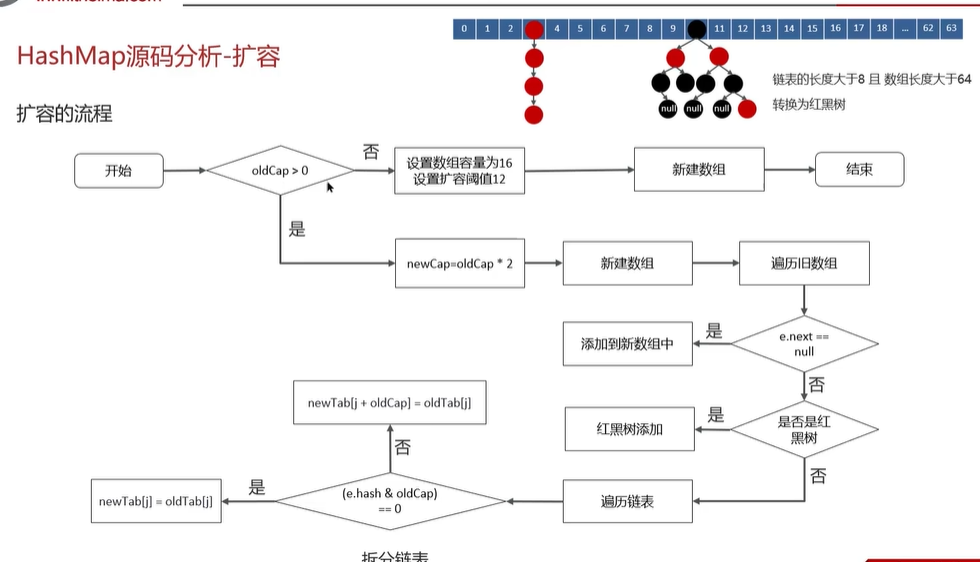
- 初始时,刚刚创建HashMap,数据为空,还没有大小,设置数组 容量为16,扩充阈值依据扩充因子计算为16* 0.75 = 12。
- 后续添加数据,若不到12个数据便不扩容
- 达到十二个数据,扩容为原来的两倍 2 * 16 = 32,然后判断当前元素hash值的位置是否为空,为空便插入
- 若是当前添加数据hash值对应位置不为空,判断是不是红黑树,是则依据红黑树规则添加
- 不是红黑树,依据链表进行遍历,对链表的哈希值与旧容量进行取模&运算,若是等于0,则位置不变,若是大于0,则依据取模结果进行偏移,得到扩容数组后链表上该元素的对应位置
按照 正确的执行顺序 重新整理 HashMap 的扩容流程,并精确描述索引位移的规则。
一、扩容触发条件
HashMap内部维护一个字段threshold(阈值) = 当前容量 × 负载因子(默认 0.75)。- 当
size(已存储的键值对数量) 大于threshold时,触发扩容。 - 例如:容量 16,阈值 12。当添加第 13 个键值对时,
size变成 13 > 12,执行扩容。
二、扩容流程(以 JDK 1.8 为例)
步骤 1:创建新数组
- 新容量 = 旧容量 << 1(即 2 倍)。
- 新阈值 = 新容量 × 负载因子。
- 创建一个长度为新容量的
Node<K,V>[] newTab。
步骤 2:遍历旧数组,将每个非空桶中的元素迁移到新数组
对于旧数组中的每个位置(桶):
- 若该位置是单个节点(无链表/红黑树):
重新计算该节点在新数组中的索引index = (newCap - 1) & hash,然后放入新数组对应位置。 - 若该位置是 链表(节点数 ≤ 树化阈值,默认为 8):
遍历链表,将链表节点拆分为低位链(索引不变)和高位链(索引 = 原索引 + oldCap),分别挂到新数组的对应位置。 - 若该位置是 红黑树(节点数 ≥ 树化阈值):
同样拆分为低位树和高位树,如果拆分后树节点数 ≤ 6,则退化为链表;否则保持树结构,并分别放到新数组的两个位置(原索引、原索引+oldCap)。
步骤 3:将新数组赋值给 table,更新 threshold 为新阈值
- 旧数组被丢弃,等待 GC 回收。
步骤 4:继续执行新元素的 put 操作(此时已经扩容完成)
- 新元素按照新数组的容量计算索引,然后插入(若空桶直接放,否则按链表/红黑树规则插入)。
三、链表拆分时的索引位移规则
为什么要做索引位移?
因为新数组长度是旧数组的 2 倍,所以元素在新数组中的索引只有两种可能:
- 保持原索引不变(
index) - 移动到原索引 + 旧容量(
index + oldCap)
判断方法(核心代码)
if ((e.hash & oldCap) == 0) {
// 加入低位链(索引不变)
} else {
// 加入高位链(索引 = 原索引 + oldCap)
}原理解释
oldCap是 2 的幂,其二进制只有一位是 1(例如 16 =10000)。e.hash & oldCap的结果只有两种:0或oldCap。- 结果为
0表示 hash 值在该位上为 0 → 新索引不变。 - 结果为
oldCap表示 hash 值在该位上为 ,新索引 = 原索引 +oldCap。
举例(oldCap = 16, newCap = 32)
- 旧索引计算:
(16-1) & hash= 取 hash 的低 4 位。 - 新索引计算:
(32-1) & hash= 取 hash 的低 5 位。 - 若 hash 的第 5 位(从 1 开始数)为 0,新索引与旧索引相同;若为 1,新索引 = 旧索引 + 16。
四、纠正你理解中的错误点
| 你的原描述 | 正确表述 |
|---|---|
| “达到十二个数据,扩容为原来的两倍,然后判断当前元素hash值的位置是否为空,为空便插入” | 扩容过程是迁移所有旧元素,与新元素插入是先后两个阶段。先完成扩容,再执行新元素插入。 |
| “对链表的哈希值与旧容量进行取模&运算,若是等于0,则位置不变,若是大于0,则依据取模结果进行偏移” | 运算结果是 0 或 oldCap,不是任意大于0的值。偏移量固定为 oldCap,不是“依据取模结果”。 |
| “取模&运算” | & 是按位与,不是取模。取模通常用 %。 |
五、完整伪代码流程(帮助你记忆)
public V put(K key, V value) {
// 1. 如果 table 为空,初始化(容量16,阈值12)
// 2. 计算 hash = key.hashCode() ^ (key.hashCode() >>> 16)
// 3. 如果当前 size > threshold,执行 resize()
- newCap = oldCap << 1
- newThr = newCap * loadFactor
- 创建 newTab
- for (每个旧桶节点) {
if (是单个节点) 直接计算新索引放入 newTab
else if (是链表) 拆分为低位链、高位链,分别放入 newTab
else if (是红黑树) 拆分为低位树、高位树,必要时退化为链表
}
- table = newTab; threshold = newThr
// 4. 根据新容量计算新元素索引 i = (newCap-1) & hash
// 5. 如果 table[i] 为空,直接放入
// 6. 否则,处理冲突(链表尾插或红黑树插入)
// 7. 更新 size,如果超过阈值再扩容(这里会循环)
}希望这个整理能帮你清晰掌握 HashMap 的扩容机制。如果有其他疑问,欢迎继续探讨。
HashMap的源码
常见属性
static final int DEFAULT_INITIAL_CAPACITY = 1<<4; // aka 16
static final floatDEFAULT_LOAD_FACTOR = O.75f;
transient HashMap.Node<K,V> table; // 存数据的数组,HashMap的内部类
transient int size; // 存储元素个数- DEFAULT_INITIAL_CAPACITY = 默认的初始容量
- DEFAULT_LOAD_FACTOR = 默认的加载因子
- 扩容阈值 == 数组容量*加载因子
构造函数
Map<String,String>map =new HashMap<>();
map.put("name", "itheima");
public HashMap() {
this.loadFactor=DEFAULT_LOAD_FACTOR; // all other fields defaulted
}- HashMap是懒惰加载,在创建对象时并没有初始化数组
- 在无参的构造函数中,设置了默认的加载因子是0.75
源码分析
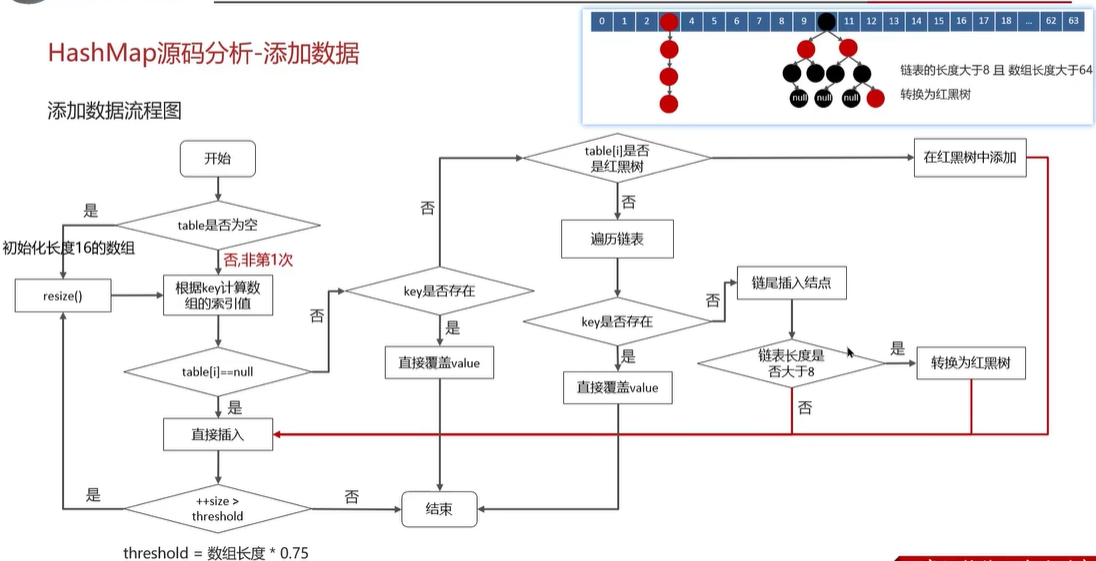
注意判断链表长度是否大于8时,若大于8,还要判断数组长度是否大于64,数组大于64,链表大于8才会转为红黑树
一、为什么容量是 2 的幂时,可以用 (e.hash & oldCap) 判断索引变化?
- 容量总是 2 的幂,比如 16(
10000)、32(100000)… 二进制只有 1 个 1,其余都是 0。 oldCap就是那个 只有 1 个 1 的数(例如10000)。e.hash是键的哈希值(经过扰动函数处理后的值,下文会解释)。e.hash & oldCap的结果:要么 0(哈希值在该位上为 0),要么 oldCap(哈希值在该位上为 1)。
为什么结果 0 表示新索引不变?
旧索引计算:
(oldCap - 1) & hash,取的是低log2(oldCap)位。新索引计算:
(newCap - 1) & hash,取的是低log2(newCap)位(比旧索引多取一位,即 oldCap 对应的那一位)。如果 oldCap 对应的那一位是 0,那么
(newCap-1) & hash的低位部分与(oldCap-1) & hash完全相同,因此新索引 = 旧索引。如果那一位是 1,则新索引 = 旧索引 + oldCap(因为高位多了一个 1)。
因为容量都是2的倍数所以二进制数都是要么10000这样一个1然后全是0,hash值其实就是当前数据在数组中的下标值,定然不会大于扩容前数组的大小,用它的二进制与扩容后的数组容量的二进制进行与运算&(同为1才为1,否则为0),计算出的值,由于容量二进制值后几位永远为0所以与&运算时,后几位也永远为0,只有第一位要么为1,要么为0,所1以无论新索引比旧索引多几位,计算出的数值永远都只有旧容量二进制值的最高位有变化,其他的都是0,这样的话,该元素在旧容量数组中的旧索引,与该元素在新容量数组中的新索引相对于旧容量的与运算,永远都是要么为0,要么就是等于旧容量,例如10000,也就是相差一个旧容量的大小。由于扩容一次是固定扩容为两倍,也就是新容量计算出的新索引的值也最多只会比就索引高一位所以计算出的结果自然就是新索引与旧索引的差值。也就是索引偏移量。
10000 10000 010000 & 01011 & 10101 & 101001 00000 10000 000000
所以判断规则就是:(e.hash & oldCap) == 0 → 索引不变(e.hash & oldCap) != 0 → 新索引 = 原索引 + oldCap
二、求哈希值时所用的 hash 是固定的吗?是多少?
1. hash 不是键的原始 hashCode,而是经过扰动函数处理后的值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}- 如果键是
null,hash = 0(固定)。 - 否则,取
hashCode的高 16 位与低 16 位进行异或(^),得到最终的hash。
2. 这个 hash 值对于同一个键是 固定不变 的
- 只要键对象不改变(且其
hashCode实现是确定的),hash就始终相同。 - 但不同的键,
hash值通常不同,没有统一的具体数值。
3. 在扩容迁移时,我们用的是这个已经计算好的 hash(存储在每个节点中)
HashMap的节点Node内部会保存该键的hash值,所以迁移时不需要重新调用hash()方法。
三、完整示例(以便你更清楚)
假设旧容量 oldCap = 16(10000),新容量 32(100000)。
某个键的 hash 二进制为 ... 0 1010(假设低 5 位是 01010)。
- 旧索引 =
(16-1) & hash=01111 & 01010=01010= 10 hash & oldCap=... & 10000= 0 (因为第 5 位是 0)→ 新索引不变,仍为 10。
另一个键的 hash 二进制低 5 位为 11010(第 5 位是 1)。
- 旧索引 =
01111 & 11010=01010= 10 hash & oldCap=... & 10000=10000= 16 (非 0)→ 新索引 = 10 + 16 = 26。
验证新索引 = (32-1) & 11010 = 11111 & 11010 = 11010 = 26,正确。
四、总结你的理解
| 你的理解 | 是否正确 | 补充说明 |
|---|---|---|
| 容量是 2 的倍数,二进制是 1000… | ✅ 正确 | 所以只有一位是 1。 |
用 & 运算代替取模,结果 0 或 oldCap | ✅ 正确 | 结果只能是这两个值。 |
| 结果为 0 表示索引不变 | ✅ 正确 | 因为 hash 在该位上为 0。 |
| 结果为 oldCap 表示索引变成 原索引 + oldCap | ✅ 正确 | 因为 hash 在该位上为 1。 |
| 求哈希值的 hash 是固定的吗? | ✅ 固定 | 同一个键的 hash 值不变(扰动后),但不同键不同。 |
如果还有疑问(比如扰动函数为什么需要 ^ (h >>> 16)),可以继续问我。
你问的“解释一下”,应该是针对上一轮回答末尾提到的 扰动函数 为什么是 hash = key.hashCode() ^ (key.hashCode() >>> 16) 吧?下面详细解释其作用。
你的理解有部分需要修正,我先澄清“高16位”和“低16位”的定义,然后解释异或、与、或运算。
一、高16位与低16位的正确理解
对于32位整数(如 hashCode),二进制表示从左到右是高位到低位。例如:
二进制: 0001 0010 0011 0100 0101 0110 0111 1000
^-------高16位-------^ ^-------低16位-------^
左边16位 右边16位- 高16位:左边的16位(高位部分)。
- 低16位:右边的16位(低位部分)。
你说“从右往左数16个二进制数”得到的是低16位(因为从最右边开始数),“从左往右数16个”得到的是高16位。虽然意思能懂,但标准术语中“高”指左边。建议记住:高 = 左,低 = 右。
二、异或运算(^)
规则:相同为0,不同为1。
| 位1 | 位2 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
示例:0101 ^ 0011 = 0110
(因为 0^0=0, 1^0=1, 0^1=1, 1^1=0)
性质:
a ^ a = 0a ^ 0 = a- 交换律、结合律
三、与运算(&)
规则:两者都为1时结果为1,否则为0。
| 位1 | 位2 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
示例:0101 & 0011 = 0001
常见用途:
- 清零特定位:
x & 0= 0 - 取低N位:
x & ( (1<<N)-1 ) - 判断奇偶:
x & 1= 0 为偶数,1为奇数
四、或运算(|)
规则:至少一个为1时结果为1。
| 位1 | 位2 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
示例:0101 | 0011 = 0111
常见用途:
- 置位特定位:
x | 0x01将最低位置1 - 合并标志位
五、为什么扰动函数用异或而不是与或?
hash = h ^ (h >>> 16) 需要将高16位信息均匀混合到低16位。
- 如果用
&:结果会偏向0(因为 1&0=0, 0&1=0, 0&0=0,只有1&1=1),导致低位大量0,分布不均。 - 如果用
|:结果会偏向1(因为 1|0=1, 0|1=1, 1|1=1,只有0|0=0),同样不均。 - 异或
^:0和1出现的概率各半(真值表中结果0和1各占一半),能保持均匀分布,因此选择异或。
希望这个解释清楚了你对位运算和扰动函数的疑问。如果还有其他细节想确认,请继续提问。
一、扰动函数的作用
HashMap 中计算键的最终哈希值的代码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}核心目的:将 hashCode 的高 16 位与低 16 位混合,降低哈希冲突,使元素在数组中的分布更均匀。
二、为什么要混合高16位和低16位?
因为 HashMap 计算数组下标时使用的是:
index = (table.length - 1) & hashtable.length是 2 的幂,比如 16、32、64… 那么(table.length - 1)的二进制低位全是 1,高位全是 0。- 例如
length = 16时,length-1 = 15二进制1111,只取hash的低 4 位。 - 如果只用
hashCode的低位,那么很多高位不同的对象,只要低位相同,就会发生冲突。
问题:hashCode 的高位信息在计算索引时被直接丢弃了,导致分布不够均匀。
解决方案:把高位信息异或到低位,让高位也影响最终的低位,从而让不同高位、相同低位的对象产生不同的索引。
三、>>> 16 和 ^ 的具体操作
h >>> 16:无符号右移 16 位,高 16 位变成 0,原高 16 位被移到了低 16 位。h ^ (h >>> 16):原始h的低 16 位与原始h的高 16 位(现在移到了低 16 位)进行异或操作。- 结果:高 16 位保持不变,低 16 位混合了原始高 16 位和低 16 位的信息。
举例(假设 32 位 int)
原始 hashCode:0x12345678
二进制:0001 0010 0011 0100 0101 0110 0111 1000
h >>> 16 = 0x00001234
二进制:0000 0000 0000 0000 0001 0010 0011 0100
h ^ (h>>>16) = 0x12345678 ^ 0x00001234 = 0x1234444C
低16位:原来低16位是 0x5678,高16位是 0x1234
异或后低16位变成 0x5678 ^ 0x1234 = 0x444C最终 hash 的低 16 位既包含了原始低 16 位(0x5678)也包含了原始高 16 位(0x1234)的信息。
四、为什么用异或(^)而不是与(&)或或(|)?
- 异或能均匀混合位信息,保持 0 和 1 的分布相对均衡。
- 与操作会使结果偏向 0,或操作偏向 1,都不利于均匀分布。
五、效果验证
假设有两个对象:
- A 的 hashCode 高 16 位 =
0x1234,低 16 位 =0x0000 - B 的 hashCode 高 16 位 =
0x0000,低 16 位 =0x1234
如果不做扰动:
- 两者低位不同,索引一般不同(但若低位恰巧相同则冲突)。
- 但若低位相同(比如都是 0x0000),则索引相同,即使高位不同。
做了扰动后:
- A 的 hash =
0x12340000 ^ 0x00001234 = 0x12341234 - B 的 hash =
0x00001234 ^ 0x00000000 = 0x00001234 - 低位完全不同,索引分散开。
六、总结
- 扰动函数 =
hashCode ^ (hashCode >>> 16) - 作用:将高 16 位信息融入低 16 位,避免仅仅因为低位相同就发生大量冲突。
- 必要性:因为
HashMap计算索引时只用低log2(capacity)位,高位信息会被丢弃;扰动后让高位影响低位,使分布更均匀,提高性能。
HashMap的jdk1.7和jdk1.8的区别
- DK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
- jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容resize()时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
HashMap在1.7的情况下的,多线程死循环问题
synchronized和ReentrantLock的区别
如果只有一个等待条件,那么 wait/notify 和 await/signal 用起来确实非常相似。灵活性的关键区别在于:一个 Lock 可以创建多个 Condition,每个 Condition 代表一个独立的等待条件,而 synchronized 的对象监视器上只能有一个隐式的条件队列。
1. 最核心的区别:多个条件队列
synchronized 的监视器只提供一个“等待室”:
synchronized (lock) {
while (条件A不满足) lock.wait();
while (条件B不满足) lock.wait();
// ...
}所有等待线程,不管是因为条件 A 还是条件 B,全都挤在同一个等待队列里。notify() 只能随机唤醒一个,notifyAll() 则会把所有人全叫醒。全叫醒后,线程们抢到锁才发现:“我的条件根本不满足”,于是继续 wait(),造成大量无效的竞争和上下文切换。
而 Lock + Condition 可以这样:
Lock lock = new ReentrantLock();
Condition conditionA = lock.newCondition(); // 用于等待条件 A
Condition conditionB = lock.newCondition(); // 用于等待条件 B- 等待条件 A 的线程调用
conditionA.await(),进入条件 A 的等待队列。 - 等待条件 B 的线程调用
conditionB.await(),进入条件 B 的等待队列。
当条件 A 变为真时,只需 conditionA.signal() 或 signalAll(),只会唤醒关心条件 A 的线程,条件 B 的线程根本不会被惊动。这就实现了精确唤醒。
2. 一个经典的对比:有界缓冲区
考虑一个缓冲区,有两个条件:满了就不能生产、空了就不能消费。
使用 synchronized + wait/notifyAll(单个等待队列)
synchronized (lock) {
while (队列满了) lock.wait(); // 生产者等待
while (队列空了) lock.wait(); // 消费者等待
// ...
lock.notifyAll(); // 全唤醒,生产者和消费者一起抢
}消费者拿走一个元素后,其实只可能让“队列满”这个条件得到缓解(应该叫醒生产者),而“队列空”的条件并没有变化(消费者自己可能还需要等待)。但 notifyAll() 把所有消费者也叫醒了,它们醒来后发现还是空,又回去睡——白白耗费 CPU。
使用 Lock + Condition(两个条件队列)
Lock lock = new ReentrantLock();
Condition notFull = lock.newCondition(); // 条件:队列不满
Condition notEmpty = lock.newCondition(); // 条件:队列不空
// 生产者
lock.lock();
try {
while (队列满了) notFull.await();
// 生产...
notEmpty.signal(); // 只叫醒一个消费者
} finally { lock.unlock(); }
// 消费者
lock.lock();
try {
while (队列空了) notEmpty.await();
// 消费...
notFull.signal(); // 只叫醒一个生产者
} finally { lock.unlock(); }结果:
- 唤醒精准,不惊扰无关线程。
- 每次只唤醒一个最可能继续执行的线程,有效减少了竞争。
- 代码语义更清晰:
notFull、notEmpty直接表达了等待原因。
3. API 级别的额外灵活性
Condition 还提供了 Object.wait() 没有的方法,进一步体现灵活性:
| Object 监视器 | Condition | 说明 |
|---|---|---|
wait() | await() | 可中断等待 |
wait(long timeout) | await(long time, TimeUnit unit) | 可指定时间单位 |
| 无 | awaitUninterruptibly() | 不可中断的等待 |
| 无 | awaitUntil(Date deadline) | 等到指定截止时间 |
仅能通过 wait(0) 形式 | 可区分 awaitNanos() 等 | 返回值能判断剩余等待时间 |
比如在某些场景里,你不想让等待被 Thread.interrupt() 打断,就可以用 awaitUninterruptibly(),这是 synchronized 无法做到的。
4. 总结:为什么说“更灵活”?
| 维度 | synchronized | Lock + Condition |
|---|---|---|
| 条件队列数量 | 一个对象只有一个 | 一把锁可以有多个 Condition |
| 唤醒控制 | 只能随机叫醒一个 / 叫醒全部 | 可以精确唤醒某一个条件队列上的线程 |
| 无效竞争 | 经常要 notifyAll,大量线程空转检查 | 只唤醒相关条件线程,大幅减少无效竞争 |
| 中断控制 | 只能响应中断 | 可选择不可中断等待 |
| 超时机制 | 仅毫秒超时,无法区分剩余时间 | 支持纳秒、截止时间,并可获取剩余等待时间 |
所以,看似都是“等待-唤醒”,但 Condition 把一个模糊的、拥挤的大通铺,变成了多个有名字、有门禁的专属等待室。这就是灵活性的本质。
当你的并发逻辑只需要一个条件时,二者差别确实不大;但一旦出现多个等待原因,Condition 的优势就立刻体现出来了。